
In the recent decade, deep neural networks (DNNs) have successfully been applied to a multitude of tasks both in research and industry.
This includes various medical applications for which DNNs have even shown to be superior to medical experts, such as with Melanoma detection. However, the reasoning of these highly complex and non-linear models is generally not transparent and as such, their decisions may be biased towards unintended or undesired features, potentially caused by data artifacts. This may lead to severe security risks when deploying these models in practice.
Revealing Data Artifacts with Explainable AI
The field of Explainable AI (XAI) brings light into the black boxes of DNNs and provides a better understanding of their decision processes. As such, global XAI methods reveal general prediction strategies employed or features encoded by a model, which can be leveraged for the identification and understanding of systematic (mis-)behavior. A popular global XAI approach is Spectral Relevance Analysis (SpRAy) [1], which automatically finds outliers in sets of local explanations for a given model, potentially caused by the use of spurious features. Another approach is Concept Relevance Propagation (CRP) [2], an XAI method that presents human-understandable concepts learned by the model, which, in turn, can be inspected to find unintended behavior.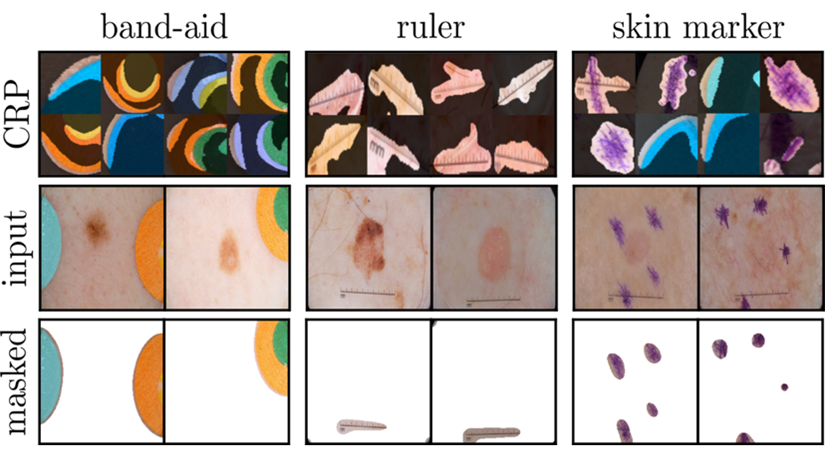
Figure 1: Data Artifacts used by a VGG-16 model trained on ISIC2019 data. We show CRP concept visualizations (top), example inputs (middle), and the cropped-out artifacts using XAI-based feature localization (bottom) for three detected artifacts (band-aid, ruler, skin marker). The method for the latter will be explained in a future blog post.
The application of both methods, SpRAy and CRP, using a VGG-16 network trained on ISIC2019 data for skin lesion classification has revealed the usage of several data artifacts, as shown in Fig. 1. This includes colorful band-aids, rulers placed next to the mole and skin markers. Here, instead of focusing on the mole, the DNN makes decisions based on data artifacts. If model outcomes for cancer risk prediction are based on these artifacts, e.g., the presence of a band-aid, this can have dangerous implications when applying the model as assistant for clinicians. The results are obtained from our recent paper on iterative XAI-based model improvement [3].
Conclusions
Using global XAI methods (SpRAy and CRP), we have revealed the usage of several data artifacts by a VGG-16 model trained on the well-known ISIC2019 dataset. As this may lead to severe security risks when employing these models in practice, we will demonstrate how to follow-up and avoid the usage of these artifacts in a following blog post.
Relevance to iToBoS
In iToBoS, many different AI systems will be trained for specific tasks, which in combination will culminate in an “AI Cognitive Assistant”. All those systems will need to be explained with suitable XAI approaches to elucidate all possible and required aspects of the systems’ decision making. Throughout the iToBoS project, we must detect and avoid the usage of data artifacts for model predictions.
Authors
Frederik Pahde, Fraunhofer Heinrich-Hertz-Institute
Maximilian Dreyer, Fraunhofer Heinrich-Hertz-Institute
Sebastian Lapuschkin, Fraunhofer Heinrich-Hertz-Institute
References
[1] Lapuschkin, S., Wäldchen, S., Binder, A., Montavon, G., Samek, W., & Müller, K. R. (2019). Unmasking Clever Hans predictors and assessing what machines really learn. Nature communications, 10(1), 1096.
[2] Achtibat, R., Dreyer, M., Eisenbraun, I., Bosse, S., Wiegand, T., Samek, W., & Lapuschkin, S. (2022). From" Where" to" What": Towards Human-Understandable Explanations through Concept Relevance Propagation. arXiv preprint arXiv:2206.03208.
[3] Pahde, F., Dreyer, M., Samek, W., & Lapuschkin, S. (2023). Reveal to Revise: An Explainable AI Life Cycle for Iterative Bias Correction of Deep Models. arXiv preprint arXiv:2303.12641.