
Deep neural networks (DNNs) are powerful tools for accurate predictions in various applications and have even shown to be superior to human experts in some domains, for instance for Melanoma detection.
However, they are vulnerable to data artifacts, such as band-aids, rulers or skin markers in the Melanoma detection task. In our previous blog posts, we have presented various approaches, both to reveal and correct model (mis-) behavior.
Reveal to Revise Framework
In this blog post, we want to introduce Reveal to Revise (R2R), a framework entailing the entire Explainable AI (XAI) life cycle, enabling practitioners to iteratively identify, mitigate, and (re-)evaluate spurious model behavior with a minimal amount of human interaction, as shown in Figure 1.
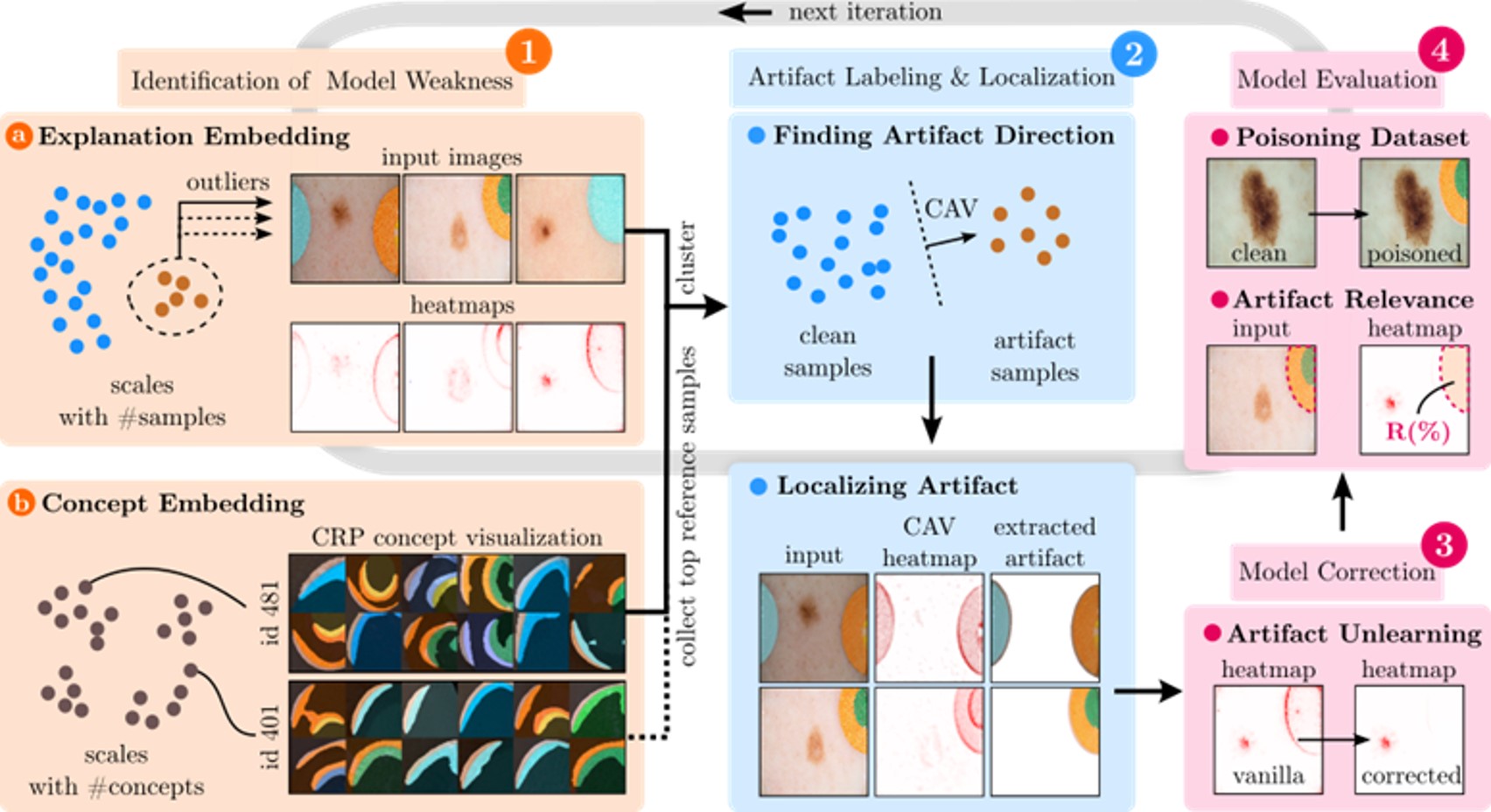 Figure 1: Reveal to Revise framework entailing the entire XAI life cycle to (1) identify model weaknesses, (2) label and localize artifacts, (3) correct the model, and (4) re-evaluate the model. The entire process can be repeated in an iterative fashion.
Figure 1: Reveal to Revise framework entailing the entire XAI life cycle to (1) identify model weaknesses, (2) label and localize artifacts, (3) correct the model, and (4) re-evaluate the model. The entire process can be repeated in an iterative fashion.
Overall, R2R consists of four steps: First (1), the potential misbehavior is identified either using Spectral Relevance Analysis [2] to automatically detect outlier behavior in large sets of local explanations, or by inspecting human-understandable concepts employed by the model using Concept Relevance Propagation (CRP) [3]. In a second step (2), the data artifact to be unlearned is modeled in latent space and localized in input space using Concept Activation Vectors. Then (3), the undesired behavior can be unlearned using various model correction methods (see previous blog post) and the model is re-evaluated by measuring the relevance left on the artifact regions and the sensitivity of its output scores to the artifact by artificially inserting the artifact into test samples. If required, the entire process can be repeated in an iterative fashion.
R2R for Melanoma Detection
We apply the R2R framework to a VGG-16 model trained on ISIC2019 data by iteratively unlearning the usage if skin marker, band-aid and ruler artifacts using the correction method Right for the Right Reason [4]. The heatmaps after each correction step for artifactual samples are shown in Figure 2. After three iterations, the model’s attention is mainly focusing on the mole itself and artifactual regions of the input image are ignored.
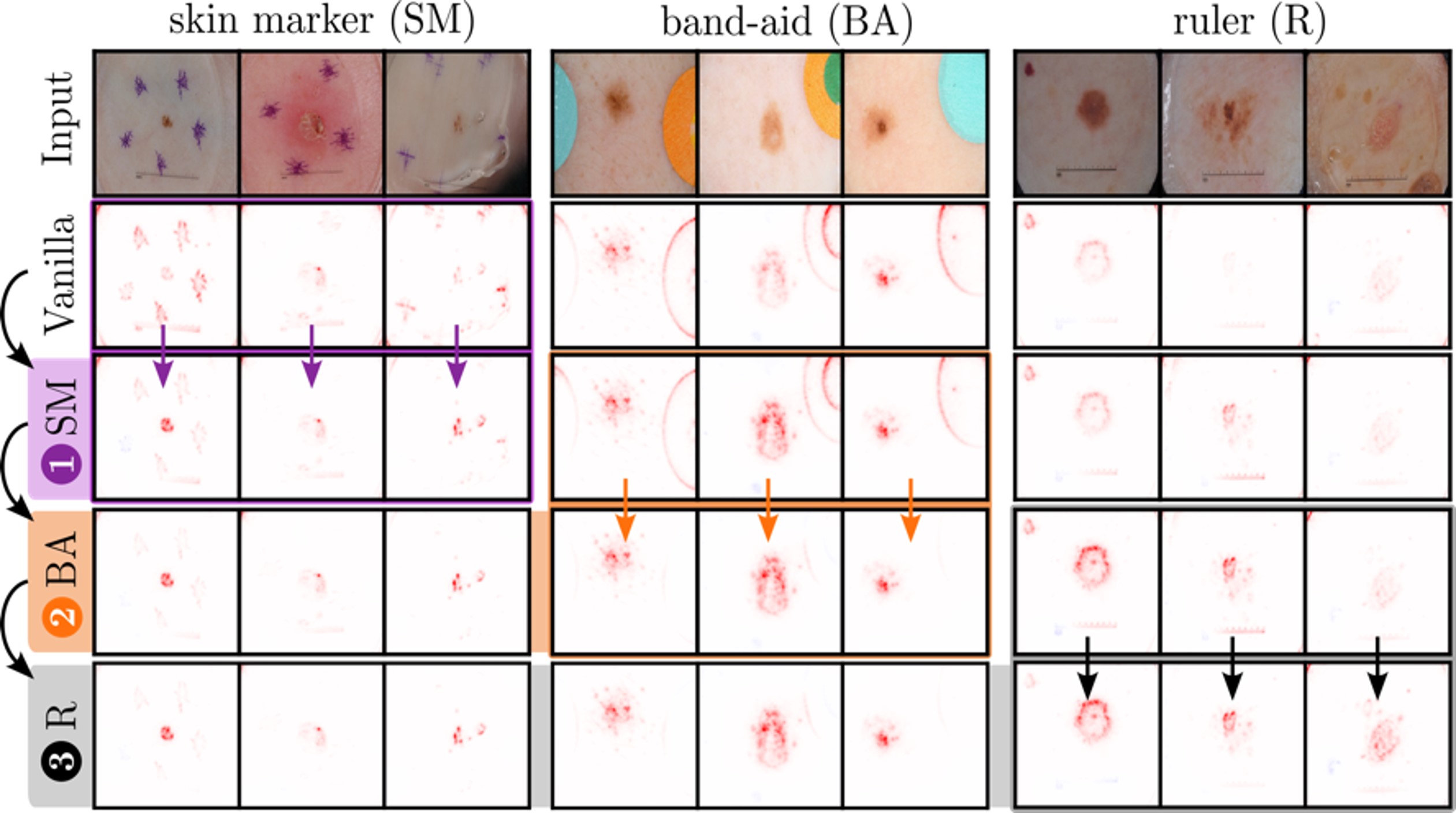 Figure 2: Application of R2R to a VGG-16 model trained on ISIC2019. In three iterations, the usages of skin marker (SM), band-aid (BA) and ruler (R) features are unlearned.
Figure 2: Application of R2R to a VGG-16 model trained on ISIC2019. In three iterations, the usages of skin marker (SM), band-aid (BA) and ruler (R) features are unlearned.
Conclusions
We introduced R2R, an XAI life cycle to reveal and revise spurious model behavior requiring minimal human interaction via high automation and demonstrated its applicability to the task of Melanoma detection. We corrected the model behavior with respect to three data artifacts, namely skin marker, band-aids and rulers. If you are interested in our work, please check out our paper.
Relevance to iToBoS
In iToBoS, many different AI systems will be trained for specific tasks, which in combination will culminate in an “AI Cognitive Assistant”. All those systems will need to be explained with suitable XAI approaches to elucidate all possible and required aspects of the systems’ decision making. Throughout the iToBoS project, we must detect and avoid the usage of data artifacts for model predictions.
Authors
Frederik Pahde, Fraunhofer Heinrich-Hertz-Institute
Maximilian Dreyer, Fraunhofer Heinrich-Hertz-Institute
Sebastian Lapuschkin, Fraunhofer Heinrich-Hertz-Institute
References
[1] Pahde, F., Dreyer, M., Samek, W., & Lapuschkin, S. (2023). Reveal to Revise: An Explainable AI Life Cycle for Iterative Bias Correction of Deep Models. arXiv preprint arXiv:2303.12641.
[2] Lapuschkin, S., Wäldchen, S., Binder, A., Montavon, G., Samek, W., & Müller, K. R. (2019). Unmasking Clever Hans predictors and assessing what machines really learn. Nature communications, 10(1), 1096.
[3] Achtibat, R., Dreyer, M., Eisenbraun, I., Bosse, S., Wiegand, T., Samek, W., & Lapuschkin, S. (2022). From" Where" to" What": Towards Human-Understandable Explanations through Concept Relevance Propagation. arXiv preprint arXiv:2206.03208.
[4] Ross, A. S., Hughes, M. C., & Doshi-Velez, F. (2017). Right for the right reasons: Training differentiable models by constraining their explanations. arXiv preprint arXiv:1703.03717.